东方理工 InfiniBand RDMA 用户手册
InfiniBand RDMA 分布式训练
RDMA(Remote Direct Memory Access)是新一代的网络传输技术,其诞生主要是为了解决网络传输中服务器端数据处理的延迟。在大规模的分布式训练任务中通过使用 RDMA 技术可以获得高吞吐、低延迟的网络通信,提升训练效率。本文将介绍如何在平台上使用 InfiniBand RDMA 进行分布式训练。
目录
1. 镜像准备
建议使用 Ubuntu 镜像,且版本在 20.04 以上。在容器内执行 cat /etc/os-release 查看镜像操作系统版本。
安装 RDMA 相关库。
apt update && apt install -y infiniband-diags perftest ibverbs-providers libibumad3 libibverbs1 libnl-3-200 libnl-route-3-200 librdmacm1
执行如下命令检查是否安装 RDMA 相关库。
dpkg -l perftest ibverbs-providers libibumad3 libibverbs1 libnl-3-200 libnl-route-3-200 librdmacm1
已安装的输出示例如下:
# dpkg -l perftest ibverbs-providers libibumad3 libibverbs1 libnl-3-200 libnl-route-3-200 librdmacm1
Desired=Unknown/Install/Remove/Purge/Hold
| Status=Not/Inst/Conf-files/Unpacked/halF-conf/Half-inst/trig-aWait/Trig-pend
|/ Err?=(none)/Reinst-required (Status,Err: uppercase=bad)
||/ Name Version Architecture Description
+++-=======================-============-============-===========================================================
ii ibverbs-providers:amd64 39.0-1 amd64 User space provider drivers for libibverbs
ii libibumad3:amd64 39.0-1 amd64 InfiniBand Userspace Management Datagram (uMAD) library
ii libibverbs1:amd64 39.0-1 amd64 Library for direct userspace use of RDMA (InfiniBand/iWARP)
ii libnl-3-200:amd64 3.5.0-0.1 amd64 library for dealing with netlink sockets
ii libnl-route-3-200:amd64 3.5.0-0.1 amd64 library for dealing with netlink sockets - route interface
ii librdmacm1:amd64 39.0-1 amd64 Library for managing RDMA connections
ii perftest 4.4+0.37-1 amd64 Infiniband verbs performance tests
平台提供可用的镜像如下。可通过 Dockerfile 基于以下镜像制作自定义镜像。
- registry.hub.com:5000/training/cuda:12.1.0-cudnn8-devel-ubuntu22.04
- registry.hub.com:5000/training/cuda:12.2.2-cudnn8-devel-ubuntu22.04
- registry.hub.com:5000/training/cuda:12.3.2-cudnn9-devel-ubuntu22.04
- registry.hub.com:5000/training/cuda:12.4.1-cudnn-devel-ubuntu22.04
- registry.hub.com:5000/training/pytorch:2.1.2-cuda12.1-cudnn8-py310-ubuntu20.04
- registry.hub.com:5000/training/pytorch:2.2.2-cuda12.1-cudnn8-py310-ubuntu22.04
- registry.hub.com:5000/training/pytorch:2.4.1-cuda12.1-cudnn9-py311-ubuntu22.04
2. 训练示例
2.1. 页面创建
创建分布式训练任务,选择 GPU 套餐,选择开启 RDMA。
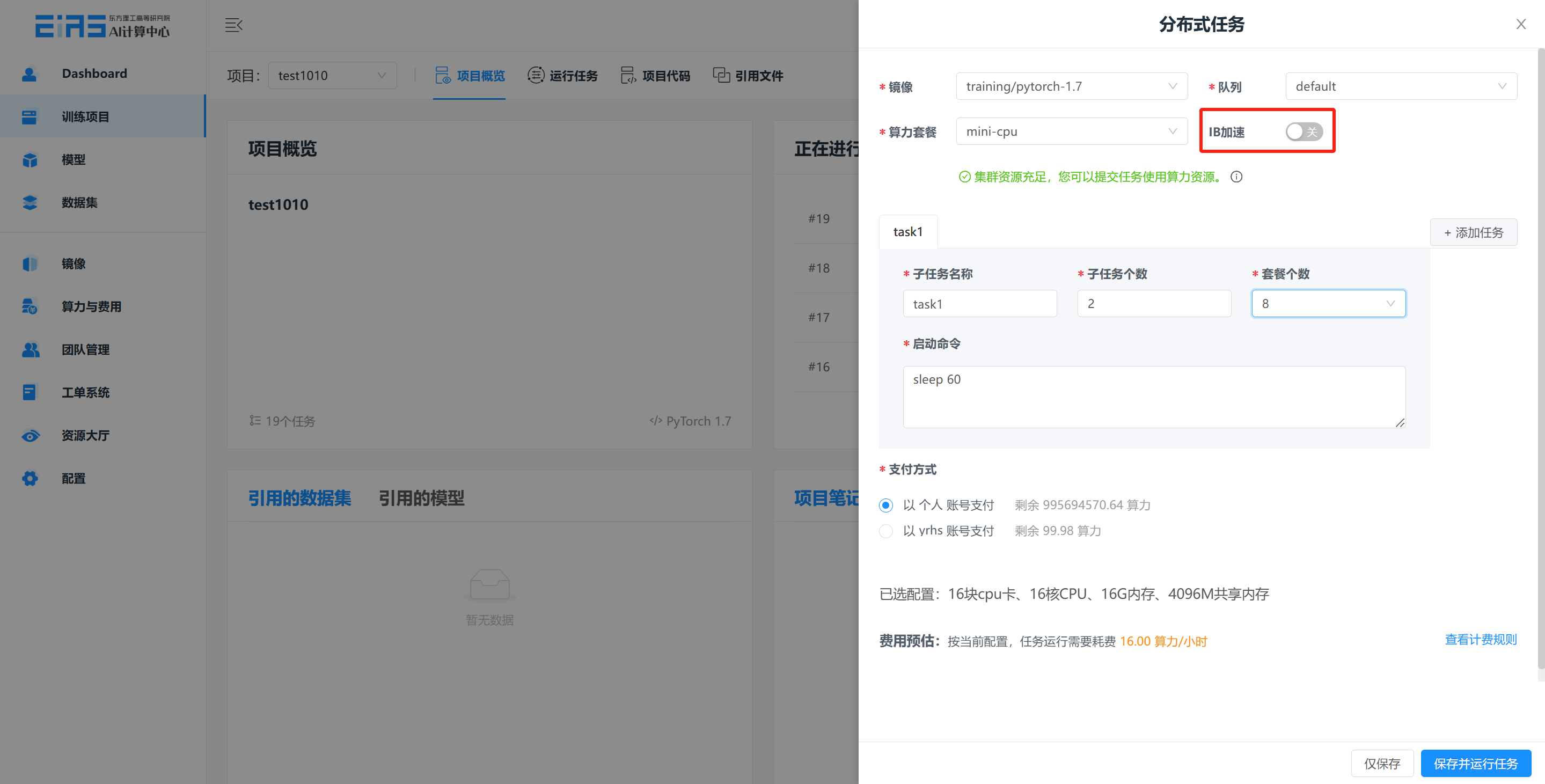
注意:仅当所选择的队列支持IB加速卡时才显示该开关,队列是否支持IB加速根据用户实际的服务器配置决定。开启IB加速后,会往容器内挂载IB网卡,多节点分布式训练过程中使用IB通信,提升任务的训练效率。另外,在创建分布式训练任务时,子任务个数一定要大于1,子任务数是容器副本数量,只有大于1,才是分布式,才会调用IB加速卡。
2.2. 环境变量
以下环境变量都非必要,都有默认值。
环境变量
NCCL_DEBUG: NCCL 日志等级,建议设置为INFO以便查看 NCCL 通信使用的网卡。详见 NCCL环境变量解释。NCCL_IB_HCA: RDMA 使用的网卡名称或网卡名称前缀,设置为mlx5。如果不设置,一些训练框架会自动寻找所有网卡,并优先使用 IB 网卡。详见 NCCL环境变量解释。NCCL_SOCKET_IFNAME: IP通信使用的网卡名称或网卡名称前缀,可不设置,平台网卡是eth。详见 NCCL环境变量解释。
注意:容器内可见的 IB 网卡有用于储存传输和 GPU 通信的,框架一般会自动寻找可用的 IB 网卡,不要将 **NCCL_IB_HCA** 设置为存储IB。
更多环境变量设置见 NCCL Environment Variables。
2.3. 启动命令
pytorch 启动 2 节点,各 8 卡训练示例,代码见附录。启动命令:
# (可选)打印出详细日志,以便查看通信是否使用 IB 网卡,而不是以太网卡
export NCCL_DEBUG=INFO
# (可选)socket 通信使用的网卡前缀
export NCCL_SOCKET_IFNAME=eth
# (可选)IB 网卡名称前缀,自动跳过不可用的 IB 网卡
export NCCL_IB_HCA=mlx5
# 其中 TASK1 是创建训练任务时填写的自任务名称的大写形式,如果填写的是其他值注意修改
export MASTER_ADDR=`echo $VC_TASK1_HOSTS | awk -F , '{print $1}'`
# 执行该命令输出当前节点 IB 网卡信息
ibstat
ibstatus
# 启动训练: --nnodes 节点数量,--nproc-per-node 每个节点 GPU 数量
torchrun --nnodes=2 --nproc-per-node=8 --rdzv-id=1 --rdzv-backend=c10d --rdzv-endpoint=${MASTER_ADDR}:29500 train.py --batch-size=128 --epochs=3
2.4. 附:代码
train.py 文件内容。
import argparse
import logging
import os
import random
logging.basicConfig(level=logging.DEBUG)
import argparse
import os
import numpy as np
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.distributed import init_process_group
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.distributed import DistributedSampler
from torchvision import datasets, transforms
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
class DummyDataset(Dataset):
def __init__(self, size):
self.size = size
self.data = [np.random.rand(1, 28, 28).astype(np.float32) for _ in range(size)]
self.target = [np.random.randint(0, 10) for _ in range(size)]
def __len__(self):
return self.size
def __getitem__(self, index):
return self.data[index], self.target[index]
def setup_ddp_env(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
print(f'WORLD_SIZE={os.getenv("WORLD_SIZE")}, LOCAL_WORLD_SIZE={os.getenv("LOCAL_WORLD_SIZE")}, '
f'RANK={os.getenv("RANK")}, LOCAL_RANK={os.getenv("LOCAL_RANK")}')
if not is_dist_training():
return
backend = 'gloo'
if args.use_cuda and torch.cuda.is_available() and args.backend == 'nccl':
backend = 'nccl'
torch.cuda.set_device(int(os.environ["LOCAL_RANK"]))
init_process_group(backend=backend)
def is_dist_training():
return int(os.getenv('WORLD_SIZE', 0)) > 0
class Trainer:
def __init__(
self,
model: torch.nn.Module,
train_data: DataLoader,
test_data: DataLoader,
optimizer: torch.optim.Optimizer,
device,
log_interval: int = 10,
) -> None:
self.local_rank = int(os.getenv("LOCAL_RANK", 0))
self.global_rank = int(os.getenv("RANK", 0))
self.device = device
self.model = model.to(device)
self.train_data = train_data
self.test_data = test_data
self.optimizer = optimizer
# self.save_every = save_every
self.epochs_run = 0
self.log_interval = log_interval
if is_dist_training():
if device.type == 'cuda':
self.model = DDP(self.model, device_ids=[self.local_rank])
else:
self.model = DDP(self.model)
else:
self.model = torch.nn.DataParallel(self.model)
def _run_batch(self, source, targets):
self.optimizer.zero_grad()
output = self.model(source)
loss = F.cross_entropy(output, targets)
loss.backward()
self.optimizer.step()
return loss
def _run_epoch(self, epoch):
b_sz = len(next(iter(self.train_data))[0])
print(f"[global_rank{self.global_rank}] Epoch {epoch} | Batchsize: {b_sz} | Steps: {len(self.train_data)}")
if is_dist_training():
self.train_data.sampler.set_epoch(epoch)
for i, (source, targets) in enumerate(self.train_data, start=1):
source = source.to(self.device)
targets = targets.to(self.device)
loss = self._run_batch(source, targets)
if i % self.log_interval == 0:
num_workers = int(os.getenv("WORLD_SIZE", 1))
print(f'Train Epoch: {epoch} [{i * len(source) * num_workers}/{len(self.train_data.dataset)} '
f'({100. * i / len(self.train_data):.0f}%)]\tloss={loss.item():.6f}')
def train(self, max_epochs: int):
self.model.train()
for epoch in range(self.epochs_run, max_epochs):
self._run_epoch(epoch)
def get_dataloaders(args):
train_loader = test_loader = None
if args.use_dummy_data > 0:
train_data = DummyDataset(args.use_dummy_data) # MNIST 60000 训练样本
train_loader = torch.utils.data.DataLoader(train_data, batch_size=args.batch_size, shuffle=True)
else:
data_dir = args.data_dir if args.data_dir else './data'
if dist.get_rank() == 0:
datasets.MNIST(data_dir, train=True, download=True)
dist.barrier()
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_data = datasets.MNIST(data_dir, train=True, download=True, transform=transform)
test_data = datasets.MNIST(data_dir, train=False, transform=transform)
sampler = DistributedSampler(train_data) if is_dist_training() else None
shuffle = True if sampler is None else False
train_loader = torch.utils.data.DataLoader(
train_data, batch_size=args.batch_size, shuffle=shuffle, pin_memory=True, sampler=sampler
)
test_loader = torch.utils.data.DataLoader(test_data, batch_size=args.test_batch_size)
return train_loader, test_loader
def get_optimizer(args, model):
optimizer = getattr(optim, args.optimizer)
optimizer = optimizer(model.parameters(), lr=args.lr)
return optimizer
def parse_args():
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
# 数据集和模型
parser.add_argument('--data-dir', type=str, default='./data', help='MNIST 数据集存储路径,目录下不存在时会自动下载数据集 (默认: ./data)')
parser.add_argument('--use-dummy-data', type=int, default=0, help='使用随机数据集,方便快速测试,数据集样本数量,不使用随机数据 (默认: 0)')
# 训练超参数
parser.add_argument('--batch-size', type=int, default=64, metavar='N', help='每个 GPU 训练使用的 batch size (默认: 64)')
parser.add_argument('--test-batch-size', type=int, default=64, metavar='N', help='每个 GPU 测试使用的 batch size (默认: 64)')
parser.add_argument('--epochs', type=int, default=14, metavar='N', help='训练 epochs 数,即把数据集训练多少遍 (默认: 14)')
parser.add_argument('--optimizer', type=str, default='Adadelta', metavar='O', help='优化器名称,可取值见 torch.optim (默认: Adadelta)')
parser.add_argument('--lr', type=float, default=0.001, metavar='LR', help='学习率 (默认: 0.001)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M', help='学习率 gamma (默认: 0.7)')
parser.add_argument('--seed', type=int, default=1, metavar='S', help='随机数种子 (默认: 1)')
# 日志与保存 checkpoint
parser.add_argument('--log-interval', type=int, default=50, metavar='N', help='每训练多少 batch 输出一次日志 (默认: 50)')
# 其他
parser.add_argument('--use-cuda', type=bool, default=True, help='当 GPU 可用时是否使用 CUDA (默认: True)')
parser.add_argument('--backend', type=str, default='nccl', choices=['nccl', 'gloo'], help='分布式训练通信库 (默认: nccl)')
parser.print_help()
return parser.parse_args()
def main():
args = parse_args()
print(args)
setup_ddp_env(args)
device = torch.device(f'cuda:{os.getenv("LOCAL_RANK", 0)}' if args.use_cuda and torch.cuda.is_available() else 'cpu')
train_loader, test_loader = get_dataloaders(args)
model = Net()
optimizer = get_optimizer(args, model)
trainer = Trainer(
model=model,
train_data=train_loader,
test_data=test_loader,
optimizer=optimizer,
device=device,
log_interval=args.log_interval
)
trainer.train(args.epochs)
if __name__ == "__main__":
main()